![]()
![]()

Creative Coding: Comic Helvetic mit Nodebox 1 und Processing.py
Ich hatte es vor ein paar Tagen angedroht, daß ich an diesem Wochenende unbedingt etwas mit der Comic Helvetic, dem Bastard aus Comic Sans und der Helvetica, anstellen wolle, denn die kostenlos zu nutzende Schrift ist nicht nur »für offizielle Dokumente« gut.
Also habe ich sie heruntergeladen und sie als Erstes in der Knotenschachtel (aka Nodebox 1) eingesetzt:
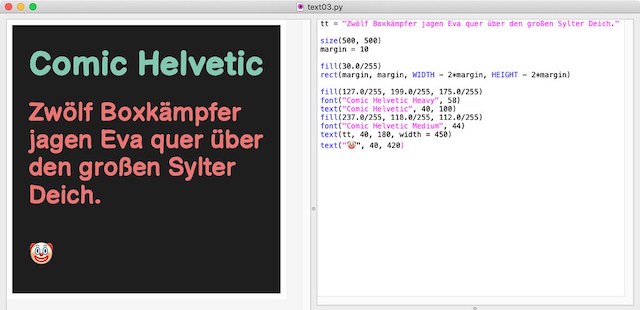
Der Quellcode ist straight forward und nur wenige Zeilen lang (das mag ich an Nodebox 1, die Knotenschachtel ist nicht sehr geschätzig 🤪):
tt = "Zwölf Boxkämpfer jagen Eva quer über den großen Sylter Deich."
size(500, 500)
margin = 10
fill(30.0/255)
rect(margin, margin, WIDTH - 2*margin, HEIGHT - 2*margin)
fill(127.0/255, 199.0/255, 175.0/255)
font("Comic Helvetic Heavy", 58)
text("Comic Helvetic", 40, 100)
fill(237.0/255, 118.0/255, 112.0/255)
font("Comic Helvetic Medium", 44)
text(tt, 40, 180, width = 450)
text("🤡", 40, 420)
Die aktuelle Version von Karsten Wolfs Fork der Nodebox läuft unter Python 3.8, daher ist sie natürlich UTF-8-fest und hat auch mit Emojis keine Probleme (siehe Screenshot).
Als Kontrast dazu wollte ich dann wissen, wie sich Processing.py mit dem Font schlägt. Ich habe dazu die Aufgabe ein wenig verschärft und das Programm wie auch die Schrift mit japanischen, chinesischen und kyrillschen Schriftzeichen gequält (siehe Screenshot und Banner im Kopf der Seite). Processing.py wie auch die Comic Helvetic kamen damit überraschend gut klar.
Der Quellcode ist ein wenig geschwätziger aber immer noch nicht ausufernd geraten:
margin = 10
def setup():
size(500, 500)
this.windowTitle(u"Seltsame Zeichen 🤡")
this.windowMove(1400, 30)
noLoop()
def draw():
background(255)
fill(30)
noStroke()
rect(margin, margin, width - 2*margin, height - 2*margin)
font = createFont("ComicHelvetic-Heavy", 58)
textFont(font)
textSize(52)
fill(127, 199, 175)
u = 70
text("Seltsame Zeichen", 20, u)
u = 110
font = createFont("Comic Helvetic", 24)
textFont(font)
textSize(24)
fill(237, 118, 112)
lines = loadStrings("boxer.txt")
for line in lines:
print(line)
text(line, 20, u, 460, 500)
u += 80
Eine Besonderheit von Processing(.py) ist, daß die mit loadStrings() geladenenen Textdateien intern als UTF-8-Dateien behandelt werden und sich das Programm selber hinter den Kulissen um die korrekte Darstellung der Glyphen kümmert. Der Programmierer selber muß sich daher um das Encoding keine Sorgen machen. Das mag zwar ein wenig inkonsistent sein, aber Processing ist nun mal keine Sprache für Informatiker, sondern für Künstlerinnen 👩🎨 und Designer. 🧑🎨
Überrascht war ich, daß die Comic Helvetic ungeachtet ihrer leicht anrüchigen Herkunft selbst als Brotschrift eine gute Figur macht. Zumindest soweit ich das beurteilen kann, doch ich bin weder Typograph noch Designer. Aber wenn ich noch Webprojekte zu gestalten hätte, könnte ich mir durchaus vorstellen, diese Schrift einzusetzen. (Höre ich da draußen jemanden aufstöhnen »Gut, daß der keine Webprojekte mehr gestalten wird«?)
Auf jeden Fall hat mir die Beschäftigung mit der Schrift Spaß gemacht. Ich glaube, ich werde mal Google Fonts nach weiteren, seltsamen Schriften durchsuchen, die man für Creative Coding-Projekte einsetzen kann. Still digging!
![]()
![]()
Über …
Der Schockwellenreiter ist seit dem 24. April 2000 das Weblog digitale Kritzelheft von Jörg Kantel (Neuköllner, EDV-Leiter Rentner, Autor, Netzaktivist und Hundesportler — Reihenfolge rein zufällig). Hier steht, was mir gefällt. Wem es nicht gefällt, der braucht ja nicht mitzulesen. Wer aber mitliest, ist herzlich willkommen und eingeladen, mitzudiskutieren!
Alle eigenen Inhalte des Schockwellenreiters stehen unter einer Creative-Commons-Lizenz, jedoch können fremde Inhalte (speziell Videos, Photos und sonstige Bilder) unter einer anderen Lizenz stehen.
Der Besuch dieser Webseite wird aktuell von der Piwik Webanalyse erfaßt. Hier können Sie der Erfassung widersprechen.
Diese Seite verwendet keine Cookies. Warum auch? Was allerdings die iframes von Amazon, YouTube und Co. machen, entzieht sich meiner Kenntnis.
Werbung
Diese Spalte wurde absichtlich leergelassen!
Werbung
