![]()
![]()

Wenn Flickr stirbt
Adrienne Lafrance fragt im Atlantic: Was passiert eigentlich mit all unseren digitalen Sammlungen, wenn Amazon stibt? Eine Frage, die auch mich schon länger umtreibt. Zwar ist bei mir das Problem nicht Amazon (den Verlust der paar Ebooks, die ich von denen auf meinem Smartphone habe, kann ich verschmerzen), mein Problem ist auch nicht YouTube. Zwar liegen dort alle meine schönen Agility-Videos, aber auch deren Zahl ist begrenzt und ich habe ein Backup auf DVDs und Festplatten. Nein, mein Problem heißt flickr: Dort habe ich in mittlerweile 10 Jahren über 26.000 Photos (in der Hauptsache von Gabi und mir) hochgeladen. Und flickr gehört zu Yahoo, einem Konzern, der in den letzten Jahren nicht gerade durch euphorische Wirtschaftsberichte aufgefallen ist. Zwar besitze ich auch von diesen Photos irgendwo Backups, aber was ist mit all den Titeln, Anmerkungen, Alben und Schlagworten, die die Sammlungen erst erschließbar machen?
Denn auch wenn man davon ausgeht (ausgehen kann), daß Amazon und eventuell auch flickr die nächsten 20 Jahre überleben werden, wäre es sehr optimistisch und vermessen, davon auszugehen, daß Amazon oder flickr auch in 100 Jahren noch existieren. Adrienne Lafrance zitiert den Medienwissenschaftler und Kulturhistoriker Siva Vaidhyanathan, der einen immensen Verlust medialer Daten das völlige Verschwinden nicht nur wissenschaftlicher Arbeiten, sondern auch persönlicher Sammlungen befürchtet. Denn Amazon und die anderen Internet-Konzerne haben
done so much to bully both readers and publishers. And yet if it were to collapse, it would cause chaos. […] At the start of the 22nd century, we are going to find ourselves in a situation with huge gaps in knowledge and culture. Because none of these companies will be around.
Doc Searls weiß darauf in »Why we need first person technologies on the Net« eine Antwort: Die Antwort heißt nicht die Förderung einer dezentralen Netzstruktur (auch wenn diese schon besser als gar nichts sind), die Antwort heißt die Förderung einer verteilten Netzstruktur, die es jedem erlaubt, unabhängig von den Medienkonzernen eigenständig im Netz zu publizieren und die Kontrolle über seine Daten zu behalten.
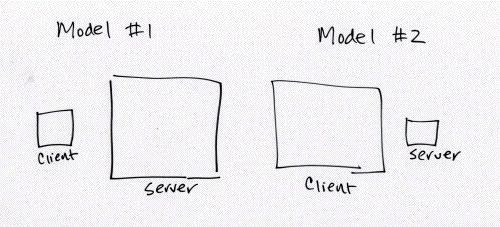
Damit wären wir natürlich wieder bei meinem Lieblingsthema. Es gilt Werkzeuge zu entwickeln, die persönliche Sammlungen und Publikationen auf einfachste Weise erstellen und sie als statische Seiten ins Netz zu stellen. Ich hatte ja vor zwei Jahren schon einmal angefangen, eine Art statisches flickr mit dem Perl Template Toolkit zu entwerfen (Teil 1, Teil 2, Teil 3 und Teil 4), dies dann aber aus Zeitmangel nicht weiter verfolgt. Zudem fand in den letzten Jahren mit dem Advent von HTML5, CSS udn JavaScript ein Paradigmenwechsel in der Webentwicklung statt, wie er in dem Beitrag von Doc Searls ebenfalls angesprochen wird. Mit dem Aufkommen der Single Page Applications (SPA) genügt es eigentlich, nur noch die Daten auf dem Server vorrätig zu halten, die Applikationslogik wird im Client (Browser, App) via JavaScript erledigt. Dave Winer hat dies in der folgenden Zeichnung als Model #2 skizziert:
Aber egal wie, damit hat man seine Bilder aus flickr immer noch nicht wieder heraus. Es gab einmal – ich glaube sogar von einem ehemaligen flickr-Mitarbeiter – einen Entwurf eines Export-Tools und eines statischen flickrs, leider weiß ich weder, wie das Teil hieß noch wo ich es finden kann. Vermutlich muß man sich daher das Rettungstool selber basteln.
Von einer anderen Seite bewegt sich Mitchell Whitelaw auf dieses Thema zu: Er findet die reinen Suchabfragen, mit denen der Nutzer die meisten digitalen Sammlungen erschließen kann, als nicht ausreichend und stellt in den digital humanities quarterly (2015, Volume 9, Number 1) Generous Interfaces for Digital Cultural Collections vor. Dem gut einstündigen Vortrag könnt Ihr auch auf obigem Video folgen.

Was passiert, wenn wir unsere Arbeit den Mediengiganten der Bewußtseinsindsutrie überlassen, prophezeit uns Josh Constine auf TechCrunsh: Twitter And Facebook Are Turning Publishers Into Ghost Writers. Und Robert Scoble fragt sich, wie Medium and Twitter could withstand Facebook’s moves to get the journalists and celebrities to move. Wie man schon aus der Überschrift erkennen kann, findet er Medium und Twitter besser als das Fratzenbuch und wirbt dafür, doch diese beiden Datensilos zu nutzen. Über eine silofreie Alternative denkt er – zumindest in diesem Aufsatz – nicht nach.
Und Chris Messina zeigt uns, wie man /slashtags zu Twitter bringt. Auf Medium. Also von Datensilo zu Datensilo im Datensilo.
Frank Schätzing hielt zum »11. nationalen Aktionstag für die Erhaltung schriftlichen Kulturgutes« am 5. September 2015 ein überragendes Plädoyer für Skepsis, Phantasie und Humanität. Und natürlich für Archive und Sammlungen: Das will ich archiviert sehen (![]() 106 KB). Er spricht zwar nicht direkt von digitalen Sammlungen, aber er meint sie sicher auch.
106 KB). Er spricht zwar nicht direkt von digitalen Sammlungen, aber er meint sie sicher auch.
War sonst noch was? Ach ja, Lorenz Matzat verreißt die neuen, selbsternannten Jugendangebote von Zeit und Spiegel: Das Gegenteil von Ambitionen: ze.tt und bento. In die gleiche Kerbe schlägt auch Thomas Knüver: Ze.tt, Byou, Bento – Wie Verlage Assistenzärzte für dumm verkaufen. Das Lesen beider Verrisse hat mir riesigen Spaß gemacht.
Und nur, damit ich es nicht vergesse: Ralf Stockmann von der Berliner Staatsbibliothek erinnert daran, daß auch URL-Shortener politisch sind Und Datensilos sein können:
Worüber aber wenig nachgedacht wird: Das Klickverhalten unserer NutzerInnen wir nun nicht nur von Facebook oder Twitter gespeichert und ausgewertet – das ist schließlich ihr Geschäftsmodell – sondern zusätzlich noch von einer weiteren, kommerziell am Markt agierenden Firma. Bei jedem einzelnen Klick auf einen gekürzten Link. Die Daten unserer NutzerInnen haben dort nichts verloren, ganz unabhängig ob die Firmen nun auf bit.ly, tinyurl.com oder einen der anderen 340 Namen hören.
Die Staatsbibliothek zu Berlin hat daher einen eigenen, datensparsamen URL-Shortener aufgesetzt, auf der Basis von YOURLS (Your Own URL Shortener), einer freien (MIT-Lizenz) Open Source Software zum Selberhosten, die Ihr Euch auf GitHub herunterladen könnt.
1 (Email-) Kommentar
Sie sprechen mir da aus der Seele.
Wir vertrauen unsere Daten Diensten an bei denen wir am Ende keine Kontrolle über diese mehr haben. Aktuelles Beispiel ist Microsoft Zune: http://www.golem.de/news/es-wird-einmal-gewesen-sein-microsofts-zune-wird-komplett-eingestellt-1509-116369.html
Da hat der Benutzer nun auch den Aufwand seine Daten zu sichern oder sogar darauf zu verzichten wenn es einem zu viel Arbeit ist. Wenn man sich nicht darum kümmert sind die Daten weg.
Ich habe schon vor langer zeit mir einen eigenen Kurz-URL Dienst gebaut: http://correptus.de/ Diese Verwende ich in meinen eigenen Blogs und Twitter Meldungen. Somit habe ich zumindest bei dieser Thematik meine Hand auf meinen Daten.
– Johannes K. (Kommentieren) (#)
![]()
![]()
Über …
Der Schockwellenreiter ist seit dem 24. April 2000 das Weblog digitale Kritzelheft von Jörg Kantel (Neuköllner, EDV-Leiter, Autor, Netzaktivist und Hundesportler — Reihenfolge rein zufällig). Hier steht, was mir gefällt. Wem es nicht gefällt, der braucht ja nicht mitzulesen. Wer aber mitliest, ist herzlich willkommen und eingeladen, mitzudiskutieren!
Alle eigenen Inhalte des Schockwellenreiters stehen unter einer Creative-Commons-Lizenz, jedoch können fremde Inhalte (speziell Videos, Photos und sonstige Bilder) unter einer anderen Lizenz stehen.
Der Besuch dieser Webseite wird aktuell von der Piwik Webanalyse erfaßt. Hier können Sie der Erfassung widersprechen.
Diese Seite verwendet keine Cookies. Warum auch? Was allerdings die iframes von Amazon, YouTube und Co. machen, entzieht sich meiner Kenntnis.
Werbung
Werbung